

There’s a lot of buzzes which goes around with “machine learning” and much of it is with the tech people. But as we are advancing into the future, our CEOs should also chase the pace. For that, I present this post on lessons for CEOs to help adapt to the changing world of machine learning.
I usually get a handful of people that come up to me to ask how they can catch up with tech. I can see the fear in their eyes. They read every day about some new breakthrough or an announcement that one of their competitors is doing something with machine learning. I do my best to ease their concerns because we are still at the beginning of the beginning. In 2019, the vast majority of machine learning projects are not fully deployed, production-level implementations. Often they are experiments. In many cases, these projects may show good results, but there are impediments with getting the project into production.

The press has overstated the adoption of machine learning so far. If you are getting started now, you are not really behind. However, that will not last. Things will evolve quickly and yesterday’s experiments will turn into real applications in the near future. To borrow an ancient Chinese proverb, the best time to start a machine learning project was five years ago. The second best time is now.
CEOs like to create strategies. You create a high-level strategy and then turn your team loose on figuring out the details. You might think that with machine learning, you need an overarching strategy that defines the purpose, techniques, and goals of what you want to accomplish. Nevertheless, that would be the WRONG thing to do.

Before you can do anything with machine learning, you need data. Machine learning needs data and a lot of it. Unfortunately, getting access to data and building a repeatable pipeline around that data tends to be the “long pole in the tent” for most machine learning projects. You will save yourself a lot of time and money if you have a tight data strategy before you start thinking about machine learning.
When I started learning about ML back in 2017, we hoped machine learning model development would be 75% or more of the work required to solve a project. Turns out that while ML is the secret sauce to the project, it may only be 25–30% of the work. Wrangling data, creating pipelines, putting the solution in production, and integrating with other systems takes a tremendous amount of effort.
Moral of the story: machine learning does not limit or reduce all the other aspects of an automation project. In many ways, due to its dependency on high-quality data, it means the non-ML parts of a project are even more important.
You’ve spent all this time and resources developing a machine learning model, and now you are ready to go live. Time to sit back and enjoy the results, right? Nope. In fact, you are just getting started with ML when you get a project into production. There are a whole host of issues that reveal themselves only once you get to production. For example, does the production data resemble the data you trained on during development? If not, you might get results you don’t expect. Are you able to even measure how well your ML model is performing in production? How do you know that it is performing well or not? How do you update the model moving forward?
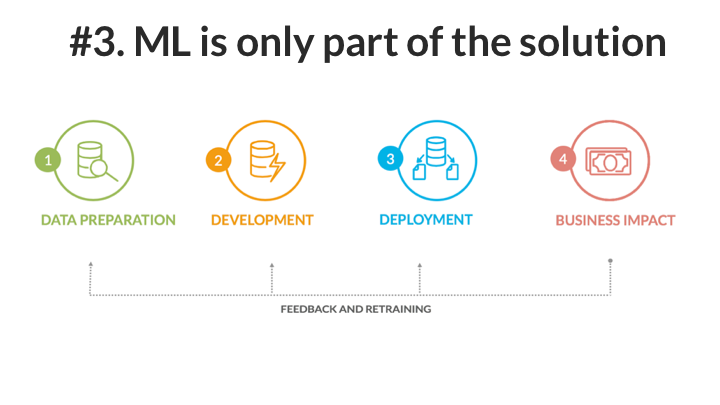 When you are deploying your first ML project to production, you should consider thinking about the production step as part of the development process, not the end of it.
When you are deploying your first ML project to production, you should consider thinking about the production step as part of the development process, not the end of it.
CEOs always have questions about hiring. Here is one that we learned by hiring 20 data scientists in a couple of years: centralize your data science function. While ML is relatively adapted by the small number of company, I’d be willing to bet that it would be a game-changer for the upcoming decade. We’ve had over 1,000 applicants to our data scientist position in one year and having this central team is a big reason for the interest.

Many companies decentralize their data scientists as if they do their software engineers. The problem with that is that data science is still a developing field. There are very few well-accepted, broadly applied data science practices. A data scientist in one company generally looks different and does different things than a data scientist in another company. That is unlike software engineering, which has been refined over many years. You can decentralize your engineers and be ok. Data scientists, on the other hand, need to work with other smart data scientists they can learn from. If you have a centralized data science team, you will be much more likely to attract data scientists instead of trying to hire a single data scientist in a department.

I get asked frequently about the impact of machine learning on the workforce. I’ve not been part of the doom-and-gloom crowd that predicts massive unemployment due to ML. I’ve been doing interviews with journalists since my first company, Automated Insights, started automating aspects of what journalists do back in 2009. The interesting point is that over the past 10 years and over a hundred implementations I’ve been involved in, I’ve not seen anyone lose their job. I’m not going to say there will be zero impact on the workforce, but I can say from my experience I haven’t seen the widespread impact, and it also hasn’t shown up in the unemployment rate, which has continued to go down over that period.
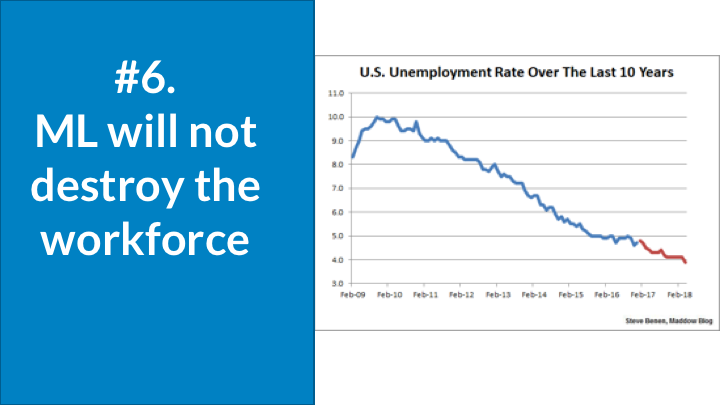
There will be volatility in the workforce. Absolutely. But there always has been volatility in the workforce and that won’t stop. I do not foresee widespread unemployment because of automation at a greater level than what we’ve seen over the past 20 years.

Some of my messages may seem a little negative on machine learning. That’s not my intent. I’m just trying to paint a realistic picture relative to some of the hype that you’ve undoubtedly read about. Ultimately, I still believe ML will be a long-term winner. It will be a pivotal part of most software solutions in the future — it just won’t be the only element of the solution. ML will be an enabling technology much like databases are today.


